不到一分钟拿到可用 PoC:Julen Garrido Estévez 测试 Burp AI

本文围绕《不到一分钟拿到可用 PoC:Julen Garrido Estévez 测试 Burp AI 》展开,重点梳理方法论、提示词风格校准和关键结果等内容,提炼背景、思路与实践注意点。
Development & Security

本文围绕《不到一分钟拿到可用 PoC:Julen Garrido Estévez 测试 Burp AI 》展开,重点梳理方法论、提示词风格校准和关键结果等内容,提炼背景、思路与实践注意点。
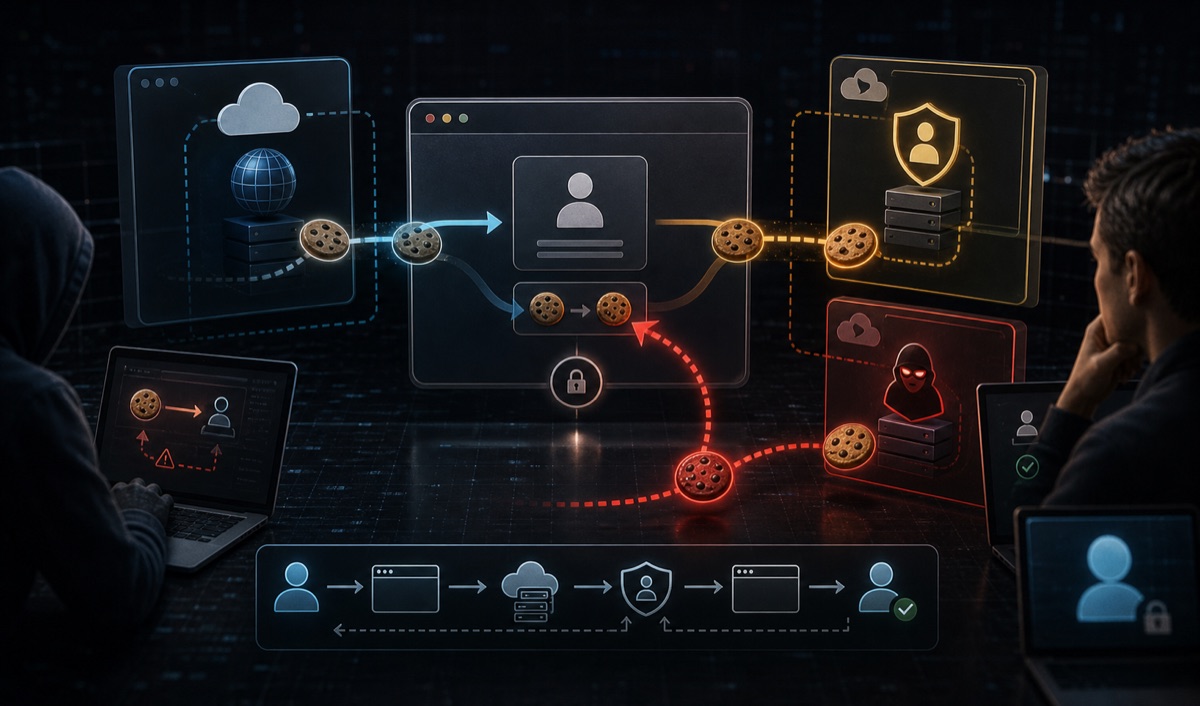
本文围绕《通过 Cookie Tossing 劫持 OAUTH 流程》展开,重点梳理什么是 Cookie Tossing?、什么是 HTTP cookies?和属性等内容,提炼背景、思路与实践注意点。
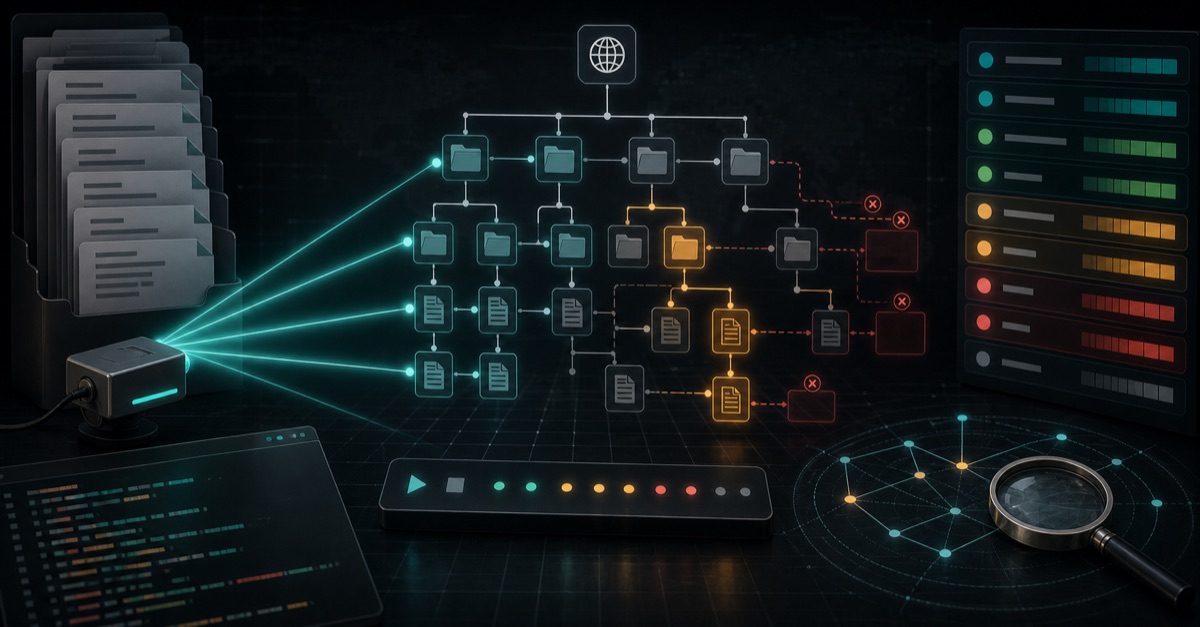
本文围绕《gobuster源码阅读--终篇》展开,重点梳理dns、s3和vhost等内容,提炼背景、思路与实践注意点。
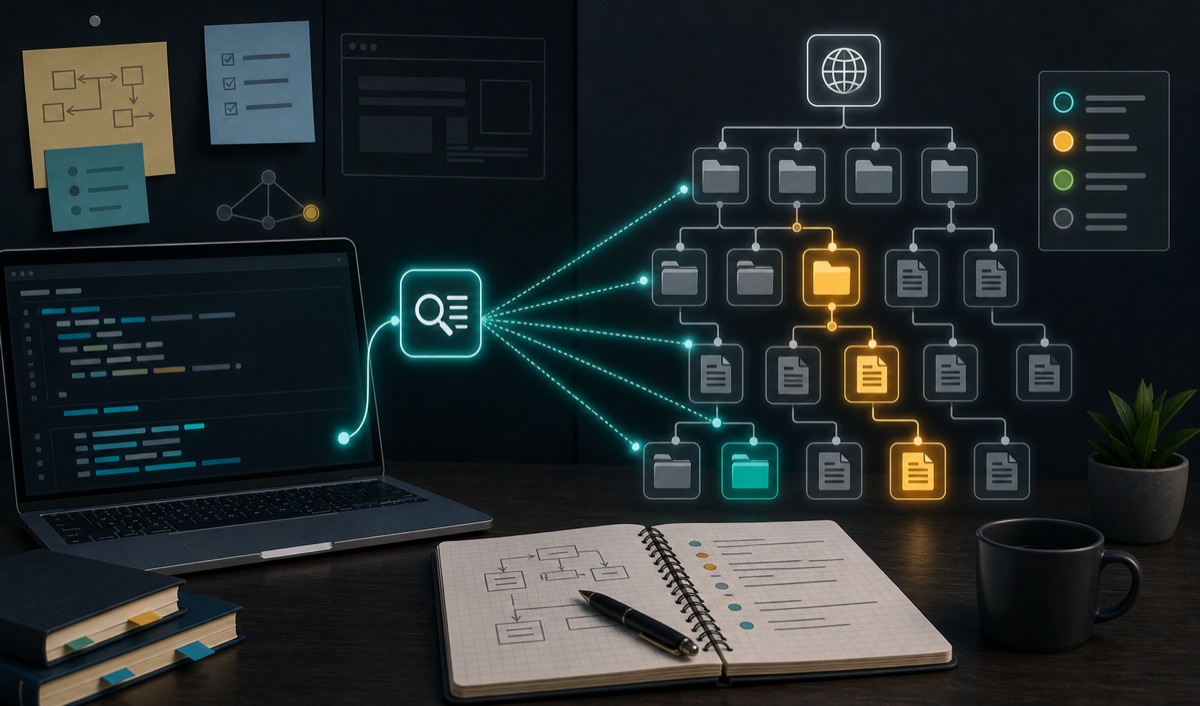
本文围绕《gobuster源码阅读--入口篇》展开,重点梳理入口、cmd和总结等内容,提炼背景、思路与实践注意点。
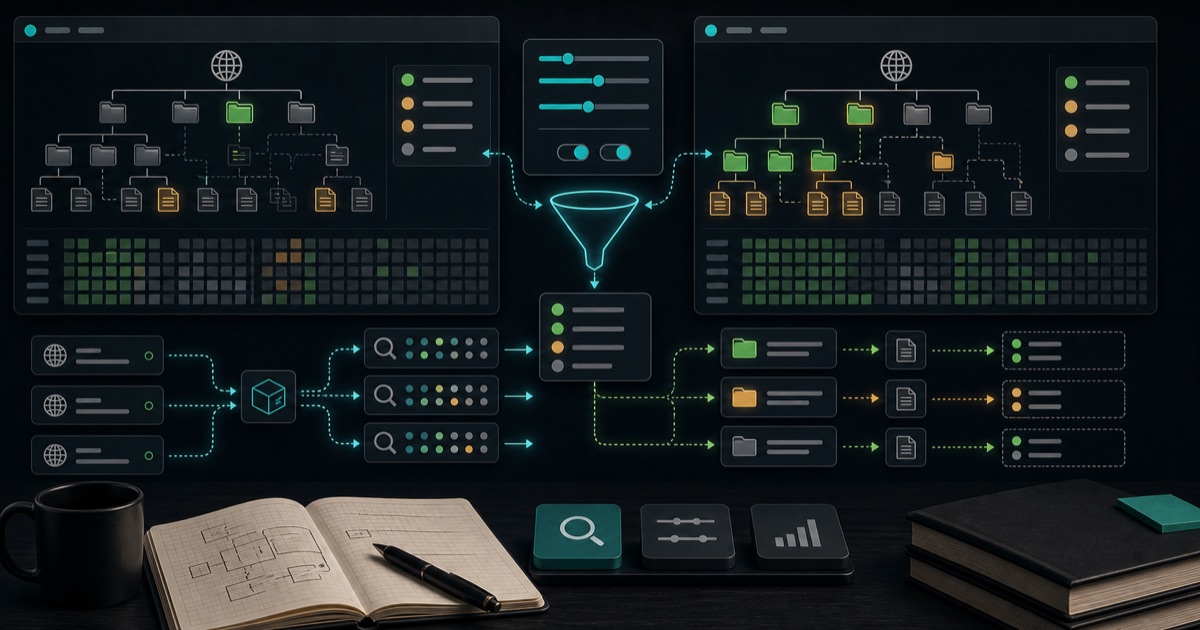
本文围绕《gobuster源码阅读--dir篇》展开,重点梳理ErrWildcard、Label和核心 worker等内容,提炼背景、思路与实践注意点。
本文围绕《SAST 测试中要测量的三个参数》展开,重点梳理定量方面、准确性和完整性等内容,提炼背景、思路与实践注意点。
本文围绕《hey,我能看到你的源码哎》梳理web安全、安全、安全开发和前端相关的背景、方法和实践细节,可作为排查与学习记录。

本文围绕《富文本场景下的 XSS》梳理安全、Web安全、Go和JavaScript相关的背景、方法和实践细节,可作为排查与学习记录。

本文围绕《JavaScript能否修改Referer请求头》梳理安全、Web安全和JavaScript相关的背景、方法和实践细节,可作为排查与学习记录。
本文围绕《白名单,被谁饶过了?》展开,重点梳理起因、apache/dubbo 的问题和URL 的其它门道等内容,提炼背景、思路与实践注意点。