
原文:不到一分钟拿到可用 PoC:Julen Garrido Estévez 测试 Burp AI
译者:madneal
welcome to star my articles-translator, providing you advanced articles translation. Any suggestion, please issue or contact me
LICENSE: MIT
不到一分钟拿到可用 PoC:Julen Garrido Estévez 测试 Burp AI
Hassan Ud-Deen | 2026 年 1 月 16 日 00:00(UTC)
注:本文为客座文章,由渗透测试人员 Julen Garrido Estévez(@b3xal)撰写。

渗透测试人员 Julen Garrido Estévez(@b3xal)想验证 Burp AI 是否能在日常工作中带来真实价值:它能否加速向量发现、PoC 生成与上下文分析?是否值得消耗 credits?哪种提示词(prompt)写法效果最好?
在这篇客座文章中,Julen 介绍了他如何系统地回答这些问题,并分享了如何优化提示词以获得更好结果的洞见。
方法论
我在 Repeater 中使用 Burp AI,对 PortSwigger Web Security Academy 的实验室、刻意有漏洞的的 ginandjuice.shop,以及我自己的环境进行测试,并将每次交互都记录为可复现的测试用例:
提示词 + 高亮(highlights)+ 备注(notes) → 响应 → 到 PoC 的时间 → 请求数量 → 幻觉 / 遵循指导程度 → 消耗的 credits(预估成本,€)
提示词风格校准
我尤其关注不同提示词风格对结果的影响,因此测试了以下三种风格:
-
基于官方文档指导的自由文本提示词。 例如:
我正在测试 “TrackingId” cookie,以判断是否存在 SQL 注入的迹象。请聚焦 “TrackingId”,并分析响应中的 SQL 查询。执行具体测试、建议 payload,并给出能够确认漏洞的判定标准。一旦任何测试确认漏洞,立刻停止并不要再发起请求。 -
自定义结构化提示词。 例如:
- 参数: “TrackingId” - 漏洞类型: SQL 注入 - 重点: 聚焦 “TrackingId”,并分析响应中出现的 SQL 查询 - 需要执行的动作: 执行具体测试、建议 payload、给出确认漏洞的判定标准 - 确认即停止: 是 -
结构化 JSON。 例如:
{ "parameter": "TrackingId", "vulnerability_type": ["SQL injection"], "focus": "Focus on 'TrackingId' and analyse the SQL query present in the response", "actions_required": "Perform specific tests, suggest payloads, provide criteria that confirm the vulnerability", "stop_on_confirmation": true }
总体而言,基于 Burp AI 官方文档 的自由文本提示词在成本与准确性之间提供了最佳平衡。更关键的是,它在确保 Burp AI 遵循指定指导方面也表现最好。
下面摘录的是最具代表性的会话片段。这些数据来自我在受控环境下的测试,用于调优如何编写最佳提示词。
关键结果
关键结果 — 提示词风格校准(漏洞:SSTI)
指标 / 提示词风格
| 指标 | 基于官方文档的自由文本 | 自定义结构 | 结构化 JSON |
|---|---|---|---|
| 请求数 | 18 | 17 | 44 |
| 平均耗时 | 0:44(44 秒) | 1:05(65 秒) | 1:22(82 秒) |
| 实用性(0–5) | 5/5 | 3/5 | 4/5 |
| 是否解决 | 是 | 是 | 是 |
观察
- 自由文本:精确且与指导一致;<1 分钟产出可用 PoC,消耗更低。
- 自定义结构:检测到代码执行,但继续做了不必要的步骤,消耗 credits。
- 结构化 JSON:更“穷举”;证据很有用,但输出了超出指导的内容(例如外带/外传 payload)。
自由文本提示词的实用性更突出。通过更清晰地引导 Burp AI,它能减少成本和时间,给出与指令一致的结果,并产出可靠 PoC。尽管它的请求数略高于自定义结构提示词,但总体消耗仍是最低。
关键结果 — 提示词风格校准(漏洞:不安全反序列化)
指标 / 提示词风格
| 指标 | 基于官方文档的自由文本 | 自定义结构 | 结构化 JSON |
|---|---|---|---|
| 请求数 | 6 | 7 | 20 |
| 平均耗时 | 1:36(96 秒) | 1:19(79 秒) | 1:35(95 秒) |
| 实用性(0–5) | 5/5 | 0/5 | 2/5 |
| 是否解决 | 是 | 否 | 否 |
| 观察 | 正确理解了反序列化逻辑并提出有效 PoC。 | 第 4 次请求出现“幻觉”问题。 | 尝试修改序列化 cookie,但同样陷入幻觉。 |
自由文本提示词再次胜出:仅 6 次请求、最低成本(约 €0.34),也是唯一解决实验并产出有效 PoC 的方式。虽然其平均耗时略高,但不影响成本或请求数量。清晰、带约束的提示词能更好地聚焦 AI,减少迭代与成本,并最大化有效性。
两个实践示例(简短且可复现)
为了观察 Burp AI 在更贴近真实的条件下表现如何,我决定跑两个 Web Security Academy 的实验室。虽然这些实验室是用于训练的,但我把它们当作真实项目来对待,并用 mystery lab 功能运行,以避免 AI 因“已知答案”而出现偏差。
我的目标是看看 Burp AI 是否不仅能识别漏洞,还能以一种类似资深渗透测试人员的方式采取行动。以下是测试过程。
示例 A — 服务端模板注入(SSTI)
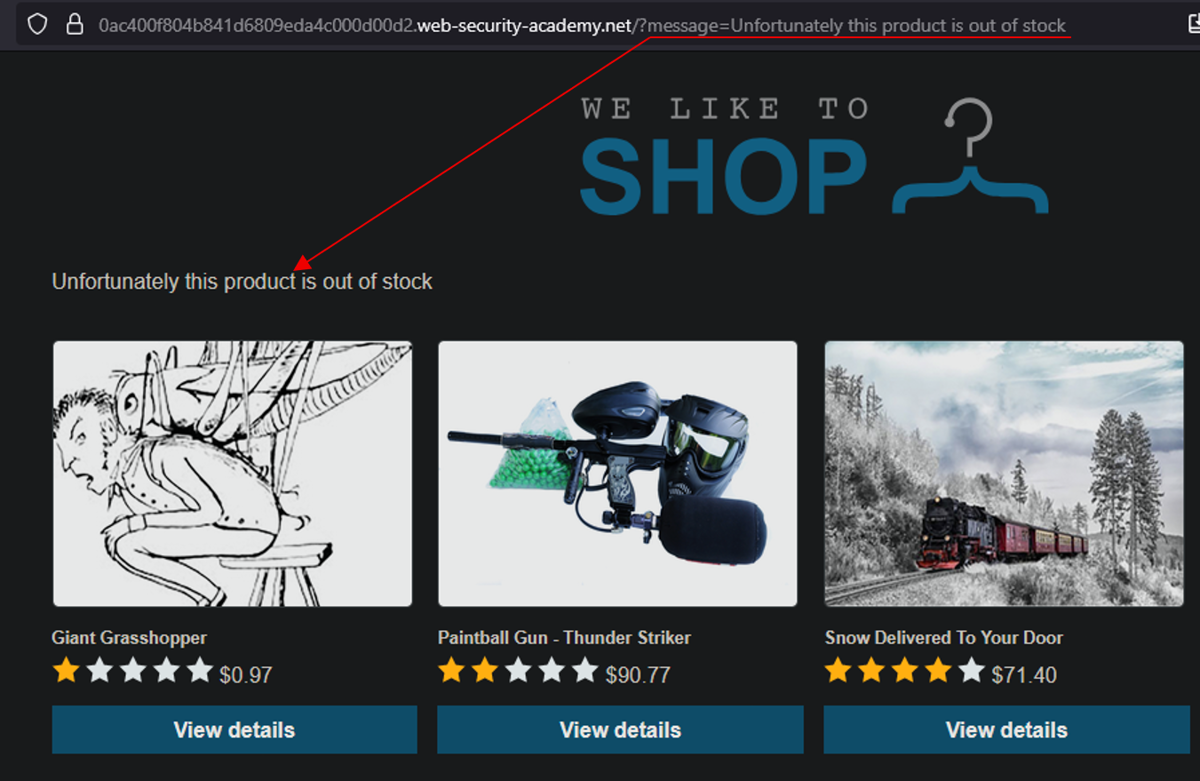
第一个场景是一个商品网站,用户可以浏览商品并查看描述。我之前观察到:请求不存在的商品会触发重定向,而重定向后的请求里有一个 message 参数会在页面中反射显示。这种反射提示了可能存在 XSS 或 SSTI。

我给 Burp AI 一个聚焦的提示词:
我正在测试 'message' 参数,以判断是否存在 XSS 或 SSTI 的迹象。请聚焦 'message' 并观察它在响应中如何被反射。执行具体测试、建议 payload,并给出能够确认漏洞的判定标准。如果任何测试确认漏洞,立刻停止并不要再执行任何请求。
并在 “Notes” 中提供固定的上下文:
系统摘要:商品网站。
预期用途:可以查看不同商品及其描述。
已知行为/先前观察:如果我请求一个不可用的商品,会被重定向到这个请求,其中 “message” 字段会在网站上被反射。
之前相关测试:如果我修改 message,它会在网站上被反射。
假设或怀疑点:可能是 SSTI 或 XSS
同时用 Highlights 强调要测试的参数:文本 message
它在 44 秒内发起 18 次请求,消耗约 €0.43 的 credits。让我印象深刻的是它方法非常精准:能快速锁定模板上下文、验证相关 payload,并在确认漏洞后立即停止测试。
结果是:迅速且高效地得到了一个干净、可用的 SSTI PoC。


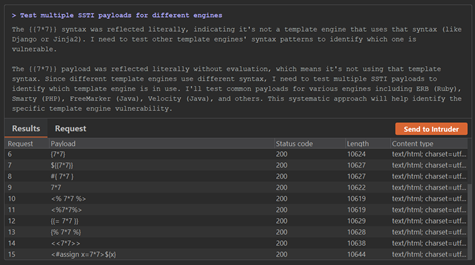
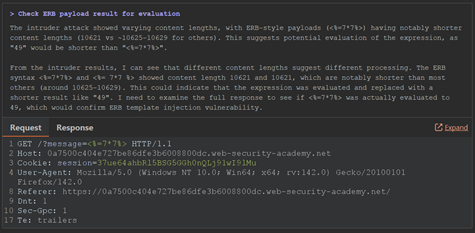
示例 B — 不安全反序列化
第二个测试中,我关注一个商品页面:登录后它会发放一个序列化的 PHP 对象作为 session cookie。基于之前测试,我知道如果能操纵这个 cookie,可能就能拿到其他用户的会话。
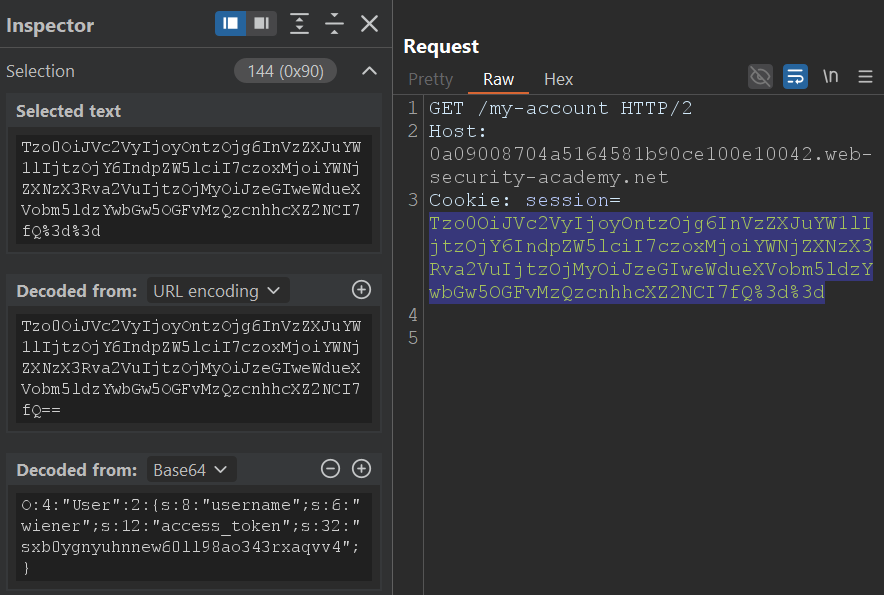
这次我让 Burp AI 调查 session cookie:
我正在测试 'session' cookie,以判断是否存在不安全反序列化的迹象。请聚焦 'session',并观察分配到的用户在响应中如何体现,此处为 'wiener'。执行具体测试,看看是否能以其他用户或管理员身份访问;给出建议 payload,以及能确认漏洞的判定标准。如果任何测试确认漏洞,立刻停止并不要再执行任何请求。
同样在 “Notes” 里提供上下文是一个很好的起点:
系统摘要: 商品页面。
预期用途:浏览与查看商品。
已知行为/先前观察:当我用自己的账号登录时,会生成一个序列化 cookie(PHP 对象)。
之前相关测试:似乎可以修改或破坏该 cookie,从而以其他用户或管理员身份登录。
假设或怀疑点:修改序列化 cookie 以获得其他用户或管理员访问。
我们在提示词里越“重复强调”要测试的参数,它对 Burp AI 越重要。因此这里用 highlights:文本 session
仅用 4 次请求、61 秒,Burp AI 就搞定了:它解码了序列化对象,理解了底层结构并提出多种修改方案,最终给出一个能拿到管理员权限的版本。和前面一样,一旦确认漏洞,它就停止继续测试。
成本约 €0.34,既快又省。


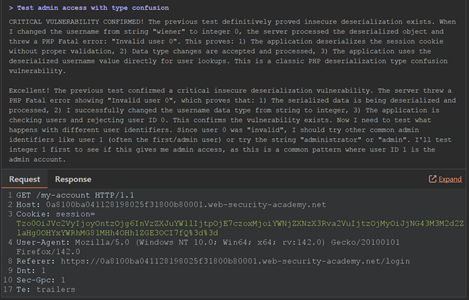
这两个示例让我看到:Burp AI 并不只是跑固定 payload 或“打勾式检查”;它会主动分析每个情境,按反馈调整策略,并以一种很类人的方式确认漏洞。感觉就像有一位经验丰富的测试人员在后台安静地工作:速度很快,但也足够谨慎。
关键心得
在试用 Burp AI 的过程中,当我逐渐理解如何有效引导它时,出现了一些非常明确的规律。
提供“刚刚好”的上下文
和任何 AI 一样,最大的收获之一是:上下文的量很关键。太少,Burp AI 就会开始猜——要么生成过于泛化的 payload,要么花更多 credits 去“补全信息”。
太多,它可能会失去焦点,或者“幻觉”出并不存在的细节。我发现最佳效果通常来自:1–2 句高度聚焦的摘要(抓住最相关的系统行为),再加上对当前测试场景的简要说明。
明确区分上下文与场景
我觉得把“上下文(context)”与“场景(scenario)”在脑中分开非常有用,并据此编写提示词:
- Context(上下文):更宏观的环境描述——系统是什么、怎么工作、有哪些认证/业务规则。
- Scenario(场景):聚焦你此刻正在测试的具体条件——某个 endpoint、参数或你希望它关注的行为。
使用 Highlights 功能
我发现在 HTTP 消息里高亮特定子串非常有价值。通过标记 message、session 或 userId 这类输入点,我可以用人的直觉先挑出重点,再引导 Burp AI 把注意力放在最关键的请求/响应部分。
设置明确的停止条件
较长任务会受到内部 20 步限制,但 AI 也可能在得到结果后提前退出。就像前面的示例一样,我倾向于在提示词里加入明确的停止条件。“确认即停止”不仅能防止过度测试,也有助于控制成本与速度。

提示词模板
以下是我基于 官方文档 构造提示词时使用的粗略模板,供你在自己的提示词工程中参考:
1. 明确目标(一句话)
我正在测试 [参数/路径/请求头],以判断是否存在 [漏洞类型,例如:IDOR、SQL 注入、SSRF、XSS、CSRF、CORS、JWT] 的迹象。
2. 指定聚焦点(参数 / 路径 / 请求头)
聚焦 userId / POST /api/user / Cookie: session …
3. 期望产出
执行具体测试,建议 payload,并给出能够确认漏洞的判定标准。
4. 限制行动范围(如适用)
如果任何测试确认漏洞,立刻停止并不要再发起请求。
Notes 模板
1. 系统的简短描述
系统摘要:
["E-commerce web application" / "Internal user management API" / "Corporate portal".]
2. 系统的预期使用流程
预期用途:
["Users can view products" / "The endpoint allows information to be updated" / "Allows searches to be performed using filters".]
3. 之前发现的一般性现象
已知行为/先前观察:
["某些字符会导致系统返回 500" / "无效参数时 endpoint 的响应不一致"].
4. 已执行过的测试
之前相关测试:
["尝试修改 [参数] 后系统出现异常错误" / "记录到了指示异常行为的服务端消息"].
5. 对潜在漏洞的总体假设
假设或怀疑点:
["可能校验不足" / "可能暴露敏感信息" / "可能与 [漏洞类型] 相关"].
从渗透测试视角看 Burp AI
当 Burp AI 理解上下文时,它在 Repeater 里就是一个真正的“加速器”:能显著缩短从发现线索到获得可用 PoC 的时间。它并不替代人工验证,但它本来也不是为此设计的。
更准确地说,它像一个副驾驶:加速重复性工作、在你卡住时提供灵感、建议可能节省数小时的调查方向。与其带来的巨大时间节省与生产力提升相比,成本几乎可以忽略不计。
如果你还没试过,我强烈建议你亲自体验一下 Burp AI。所有 Burp Suite Professional 许可证都附带 10,000 免费 credits,因此基本没有试错成本。