
原文:“steganography” - obfuscating PDF exploits in depth
译者:neal1991
welcome to star my articles-translator, providing you advanced articles translation. Any suggestion, please issue or contact me
LICENSE: MIT
上礼拜发现的关于使用 this.getPageNumWords() & this.getPageNthWord() 方法来进行混淆的 PDF 漏洞不久,我们发现另外一个,一个在 PDF 漏洞中更加强大的混淆利用技术。这种技术使用所谓的“隐写术”方法来隐藏嵌入在 PDF 文件中的图像中的恶意 Javascript 代码,它非常强大,因为它可以绕过几乎所有的 AV 引擎。
我们的 EdgeLogic 引擎将样本检测为 “exploit CVE-2013-3346”,与前一个相同。
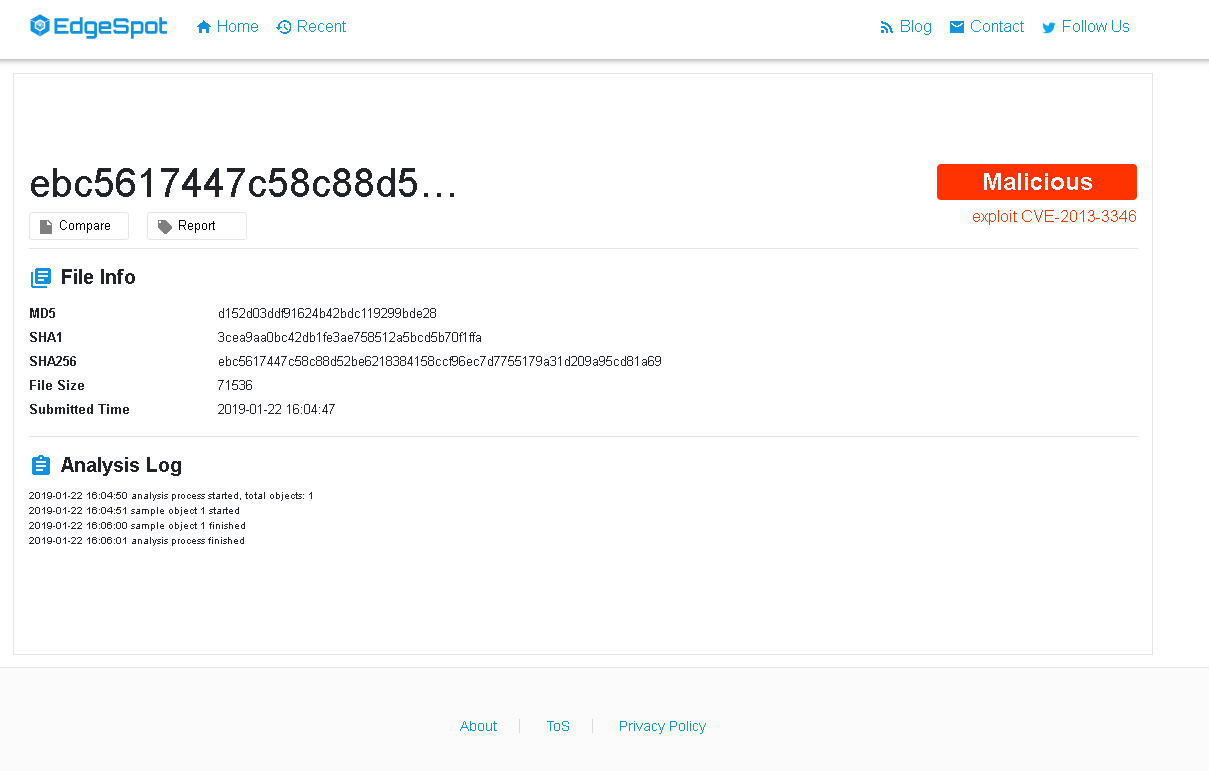
样本首先在 2017-10-10 提交给 VirusTotal,文件名为 “oral-b oxyjet spec.pdf”。

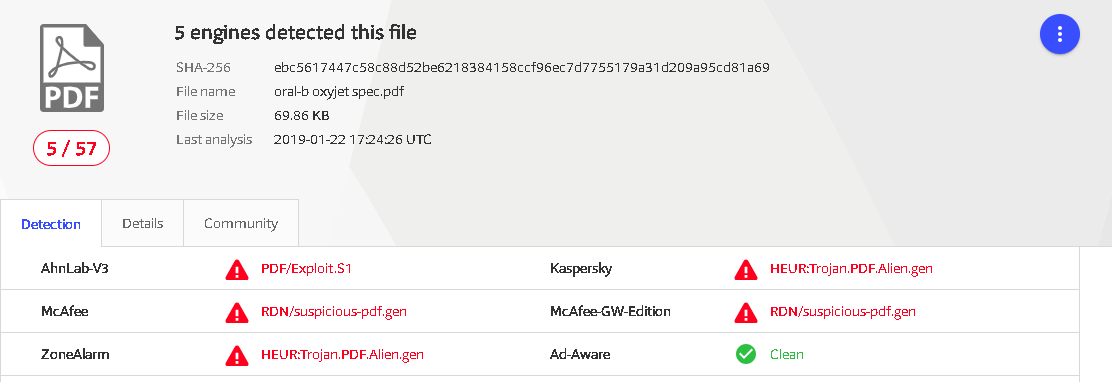
上周只有 1 个 AV 引擎检测到这种攻击(但是,截至写作时,检测增加到 5/57)。
打开后,伪装成 IRS 文件的 PDF 看起来很正常。

在该样本中使用两层混淆。 第一层是我们之前公开的 - “this.getPageNumWords()” 以及 “this.getPageNthWord()” 方法。该漏洞使用 “this.getPageNumWords()” 以及 “this.getPageNthWord()” 来读取和执行隐藏为“内容”的 Javascript。 相关代码可以在 PDF stream-64中找到。

stream-64
第二层是新的,这是我们本文的重点。 “Javascript 内容”存储在 stream-119 中,让我们看看它什么样。

美化 Javascript 后,显示如下:

为了弄清楚 Javascript 做了什么,我们首先需要学习这两个 PDF JS API,this.getIcon() 和 util.iconStreamFromIcon()。 以下是 Adobe 参考文献的摘录。


根据 API 参考资料,这两个 API 协同工作,用于读取存储在 PDF 文件中的名为 “icon” 的图像流。
通过检查上面的 Javascript 代码,我们发现代码的功能是读取和解码隐藏在图标流中的“消息”。 一旦成功读取“消息”,它将通过 “eval(msg)” 执行“消息”作为 Javascript 代码。
object-131 中名为 “icon” 的图标流可以保存为 “jpg” 文件,并在图像查看器中查看,没有问题。 如下所示:

当图像仍然可见时,恶意数据隐藏在图像中
然而,图标文件中没有可疑数据,因为恶意代码数据被严重混淆。
最终执行的 Javascript 是什么样的?在成功去混淆之后,这是一段真实的代码。

因此,我们确认这个漏洞利用为 CVE-2013-3346。
此外,我们推断该样本和前一个来自同一作者,原因如下。 他们都利用相同的漏洞 (CVE-2013-3346)。这两个漏洞利用中 Javascript 代码的相似性。 经过一些谷歌搜索,我们发现攻击者可能复制了一个名为 “steganography.js” 的项目/技术,开源在这里。该项目是在浏览器上开发的。 我们相信 PDF 样本背后的人在成功利用 PDF 格式的技术时进行了创新。我们之前在 PDF 漏洞中找不到任何提及此类技术的信息,因此我们相信这是第一次使用“隐写术”技术隐藏 PDF 漏洞。
总结
我们对这种技术印象深刻,这种技术非常适合 PDF 漏洞的恶意代码混淆。通过使用这种技术所有流看起来都很正常,所有图像都是可见的,一切看起来都合法。这可以解释为什么几乎所有 AV 引擎都没有识别它。
在这篇博客中,我们研究了用于混淆 PDF 漏洞的真正先进的“隐写术”技术,这是我们的 EdgeLogic 引擎的强大功能,因为我们能够击败这种混淆技术,以及其他许多技术。
就像前一个一样,“隐写术”技术不仅可以用于混淆这种利用(CVE-2013-3346),而且还可以应用于许多其他PDF 漏洞,包括零天。我们要求安全维护者密切关注它。
通过 @EdgeSpot_io 追随我们。