改三个 JSON,让 Claude 桌面版用上你自己的 API
Claude Desktop 默认只能官方账号登录。本文基于 cc-switch 源码分析与实操,讲解如何利用官方内置的 3p 企业网关模式,通过三个 JSON 配置文件让桌面版接入任意 Anthropic 兼容 API,并复用 Claude Code CLI 的现有配置。
Development & Security

Claude Desktop 默认只能官方账号登录。本文基于 cc-switch 源码分析与实操,讲解如何利用官方内置的 3p 企业网关模式,通过三个 JSON 配置文件让桌面版接入任意 Anthropic 兼容 API,并复用 Claude Code CLI 的现有配置。

本文围绕《从1243元跌回935元:近一年黄金到底变弱了吗?》展开,重点梳理1. 先看近一年的结论和2. 近一年日线和均线:主升结束了吗?等内容,提炼背景、思路与实践注意点。

本文围绕《博客考古:从漏洞、工具到生活折腾》展开,重点梳理前言、安全:从看热闹到修系统和安全工程:不只是把洞挖出来等内容,提炼背景、思路与实践注意点。

本文围绕《不到一分钟拿到可用 PoC:Julen Garrido Estévez 测试 Burp AI 》展开,重点梳理方法论、提示词风格校准和关键结果等内容,提炼背景、思路与实践注意点。

本文围绕《Go 版本不一致?别慌,这是特性!》展开,重点梳理故事的开端:一场“奇葩”的争论和AI 的“第一次接触”:危言耸听等内容,提炼背景、思路与实践注意点。
本文围绕《AI 审代码,靠谱吗?》展开,重点梳理背景:一道出乎意料的笔试题、初探源码:First 函数的内部实现和AI 怎么说?等内容,提炼背景、思路与实践注意点。

本文围绕《CVE-2025-55188:7-Zip 任意文件写入漏洞》展开,重点梳理相关文章等内容,提炼背景、思路与实践注意点。

本文围绕《mac mini,真香?》展开,重点梳理5K显示器横向对比(5120×2880分辨率)、主机对比和键盘等内容,提炼背景、思路与实践注意点。
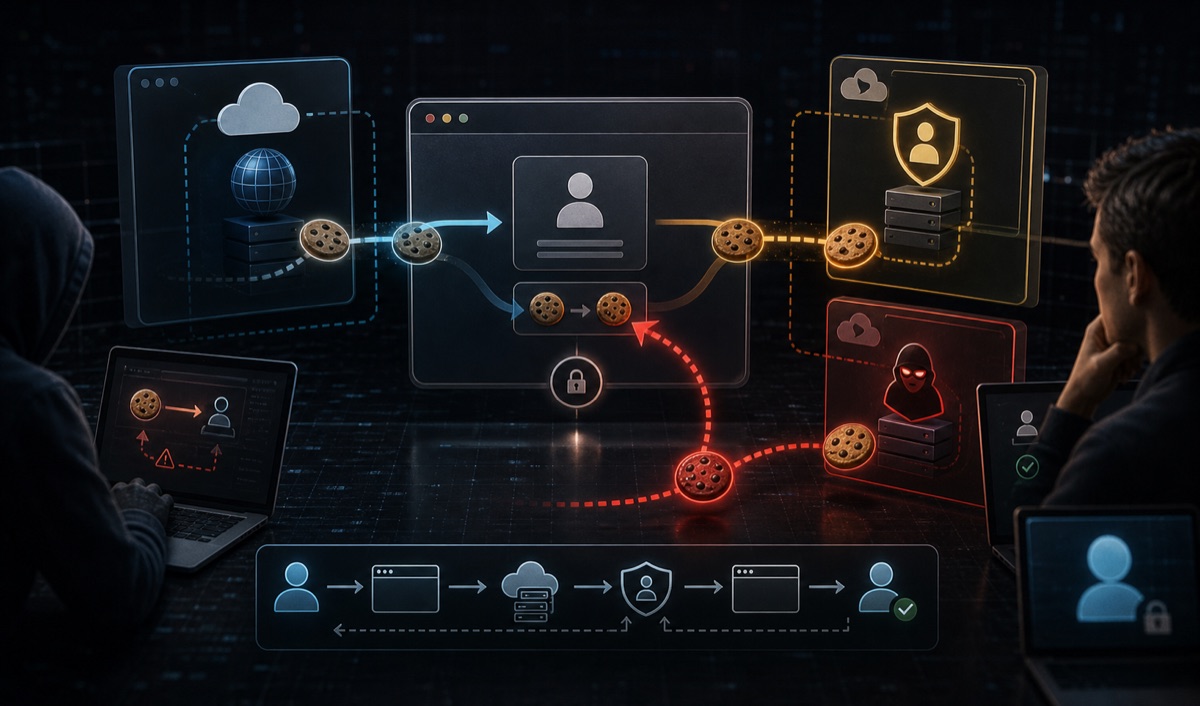
本文围绕《通过 Cookie Tossing 劫持 OAUTH 流程》展开,重点梳理什么是 Cookie Tossing?、什么是 HTTP cookies?和属性等内容,提炼背景、思路与实践注意点。

本文围绕《NilAway:实用的 Go Nil Panic 检测方式》展开,重点梳理nil panic 问题、NilAway 的核心理念和NilAway 的设计和实现等内容,提炼背景、思路与实践注意点。